问答平台(8),常见面试题
MySQL
存储引擎
MyISAM、Memory、InnoDB、Archive和NDB。
InnoDB 和 NDB 支持事务,但 NDB 支持集群。
事务
事务的特性(ACID)
原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
事务的隔离性
并发异常:第一类丢失更新、第二类丢失更新、脏读、不可重复读、幻读
隔离级别:Read Uncommitted、Read Committed、Repeatable Read、Serializable
Spirng 事务管理:
1.声明式事务(通过 xml 配置、通过注解 @Transactional)
2.编程式事务(通过 TransactionTemplate 管理事务,并通过它执行数据库的操作)
锁
范围
表级锁:开销小、加锁快,发生锁冲突的概率高、并发度低,不会出现死锁。
行级锁:开销大、加锁慢,发生锁冲突的概率低、并发度高,会出现死锁。
MyISAM 默认表级锁,InnoDB 支持行级锁。
类型(InnoDB)
共享锁(S):行级,读取一行。
排他锁(X):行级,更新一行。
意向共享锁(IS):表级,准备加共享锁。
意向排他锁(IX):表级,准备加排他锁。
间隙锁(NK):行级,使用范围条件时,对范围内不存在的记录加锁。一是为了防止幻读,二是为了满足恢复和复制的需要。
加锁
增加行级锁之前,InnoDB 会自动给表加意向锁。
执行 DML 语句时,InnoDB 会自动给数据加排他锁。
执行 DQL 语句时:
共享锁(S):SELECT … FROM … WHERE … LOCK IN SHARE MODE;
排他锁(X):SELECT … FROM … WHERE … FOR UPDATE;
间隙锁(NK):上述 SQL 采用范围条件时,InnoDB 对不存在的记录自动加间隙锁。
死锁
解决方案:
1.InnoDB 会自动检测到,并使一个事务回滚,另一个事务继续。
2.设置超时等待参数: innodb_lock_wait_timeout。
避免死锁:
1.不同的业务并发访问多个表时,约定以相同的顺序来访问这些表。
2.以批量的方式处理数据时,事先对数据排序,保证线程按固定的顺序来处据。
3.在事务中,如果要更新记录,直接申请足够级别的锁,即排他锁。
实现机制
悲观锁(数据库):针对更新数据频繁的情况。
乐观锁(自定义):针对查询数据频繁的情况(版本号机制、CAS 算法)。
索引
B+Tree(InnoDB)
数据分块存储,每一块称为一页。
所有的值按顺序存储,每一个叶子到根的距离相同。
非叶节点存储数据的边界,叶子节点存储指向数据行的指针。
通过边界缩小数据的范围,避免全表扫描,加快查找的速度。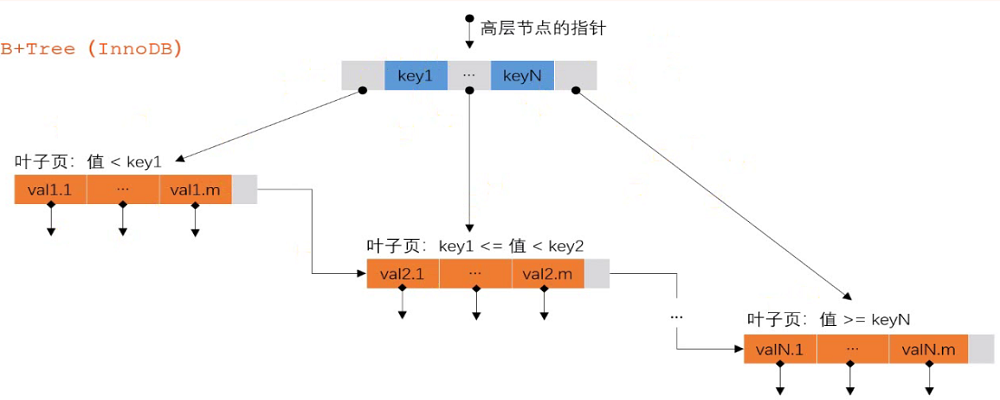
Redis
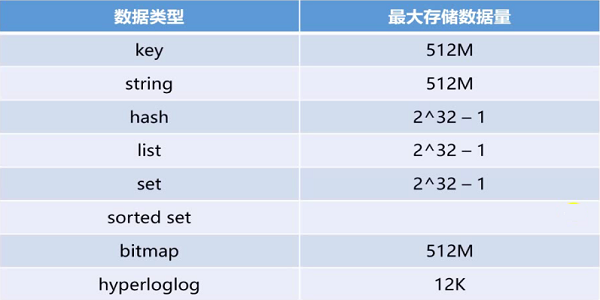
数据类型
过期策略
Redis 会把设置了过期时间的 key 放入一个独立的字典里,在 key 过期时不会立刻删除它。
Redis 通过如下两种策略,来删除过期的 key:
1.惰性删除:客户端访问某个 key 时,Redis 会检查该 key 是否过期,若过期则删除。
2.定期扫描:Redis 默认每秒执行10次过期扫描(配置hz选项),扫描策略如下
(1)从过期字典中随机选择20个 key;
(2)删除这20个key中已过期的 key;
(3)如果过期的 key 的比例超过25%,则重复步骤(1)。
淘汰策略
当 Redis 占用内存超出最大限制(maxmemory)时,让 Redis 淘汰一些数据,腾出空间继续提供读写服务,可采用如下策略(maxmemory-policy):
volatile-ttl: 在设置了过期时间的 key 中,选择剩余寿命(TTL)最短的 key,将其淘汰。
volatile-lru: 在设置了过期时间的 key 中,选择最少使用的 key(LRU),将其淘汰。
volatile-random: 在设置了过期时间的 key 中,随机选择一些 key,将其淘汰。
allkeys-lru: 在所有的 key 中,选择最少使用的 key(LRU),将其淘汰。
allkeys-random: 在所有的 key 中,随机选择一些 key,将其淘汰。
no-eviction: 禁⽌驱逐数据,当内存不⾜以容纳新写⼊数据时,新写⼊操作会报错。对可能导致增大内存的命令返回错误。
缓存穿透
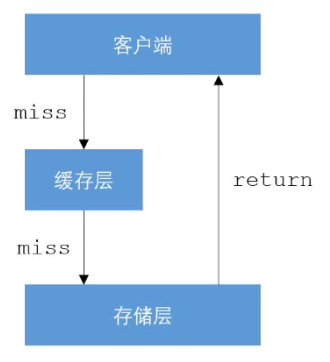
场景
查询不存在的数据,使请求直达存储层,导致负载过大,甚至宕机。
解决方案
1.缓存空对象。存储层未命中后,仍然将空值存入缓存层。再次访问该数据时,缓存层会直接返回空值。
2.布隆过滤器。将所有存在的 key 提前存入布隆过滤器,在访问缓存层之前,先通过过滤器拦截,若请求的是不存在的 key,直接返回空值。
缓存击穿
场景
热点数据,它的访问量非常大。在其缓存失效瞬间,大量请求直达存储层,导致服务崩溃。
解决方案
1.加互斥锁。对数据的访问加互斥锁,当一个线程访问该数据时,其他线程只能等待。这个线程访问过后,缓存中的数据将被重建,届时其他线程直接从缓存取值。
2.永不过期。不设置过期时间,所以不会出现上述问题,这是“物理”上的不过期。为每个 value 设置逻辑过期时间,当发现该值逻辑过期时,使用单独的线程重建缓存。
缓存雪崩
场景
缓存同一时间大面积失效,所以后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩溃。
(缓存层不能提供服务,导致所有的请求直达存储层,造成存储层宕机。)
解决方案
1.避免同时过期。设置过期时间时,附加一个随机数,避免大量的 key 同时过期。
2.构建高可用的 Redis 缓存。部署多个 Redis 实例,个别节点宕机,依然可以保持服务的整体可用。
3.构建多级缓存。增加本地缓存,在存储层前面多加一级屏障,降低请求直达存储层的几率。
4.启动限流和降级措施。对存储层增加限流措施(限流框架),当请求超出限制时,对其提供降级服务(降级自定义)。
分布式锁
场景
修改时,经常需要先将数据读取到内存,在内存中修改后再存回去。
在分布式应用中,可能多个进程同时执行上述操作,而读取和修改非原子操作,所以会产生冲突。
增加分布式锁,可以解决此类问题。
基本原理
同步锁:多个(线程)都能访问到的地方,做一个标记,标识该数据的访问权限。
分布式锁:多个(进程)都能访问到的地方,做一个标记,标识该数据的访问权限。
实现方式
1.基于数据库实现分布式锁。
2.基于 Redis 实现分布式锁。
3.基于 Zookeeper 实现分布式锁。
Redis 实现分布式锁的原则
1.安全属性:独享。在任一时刻,只有一个客户端持有锁。
2.活性A:无死锁。即使持有锁的客户端崩溃或网络被分裂,锁仍然可以被获取。
3.活性B:容错。只要大部分 Redis 节点都活着,客户端就可以获取和释放锁。
单 Redis 实例实现分布式锁
1.获取锁使用命令:
1 | |
NX: 仅在 key 不存在时才执行成功。
PX: 设置锁的自动过期时间。
2.通过 Lua 脚本释放锁,可以避免删除别的客户端获取成功的锁:
A加锁 -> A阻塞 -> 因超时释放锁 -> B加锁 -> A恢复 -> 释放锁
多 Redis 实例实现分布式锁
Redlock 算法,该算法有现成的实现,Java版本的库为 Redisson。
算法流程:
1.获取当前 Unix 时间,以毫秒为单位。
2.依次尝试 N 个实例,使用相同的 key 和随机值获取锁,并设置响应超时时间。如果服务器没有在规定时间内响应,客户端应该尽快尝试另一个 Redis 实例。
3.客户端使用当前时间减去开始获取锁的时间,得到获取锁使用的时间。仅当大多数的 Redis 节点都取到锁,并且使用的时间小于锁失效的时间,锁才算取得成功。
4.如果取到了锁,key 的真正有效时间等于有效时间减去获取锁使用的时间。
5.如果获取锁失败,客户端应该在所有的 Redis 实例上进行解锁。
Spring
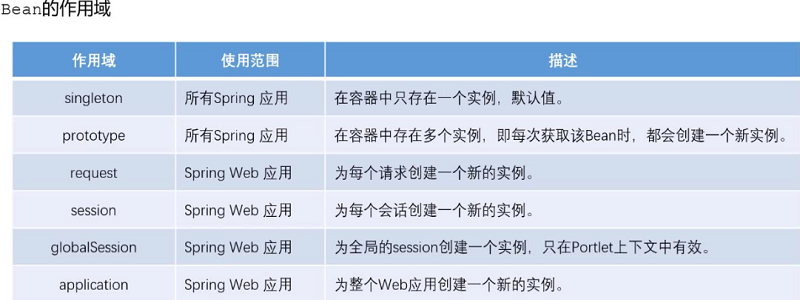
Spring IoC
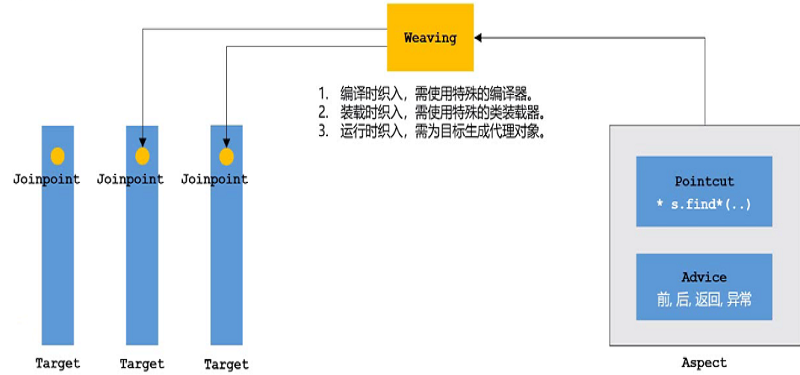
Spring AOP
Spring MVC
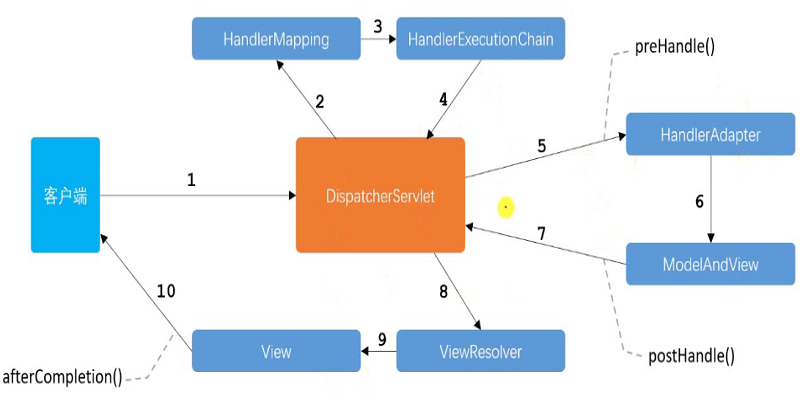
Spring MVC 处理请求的过程